【总结】LLM论文阅读(入门篇)-第一周
深度学习和Transformer
RNN和LSTM都是通过递归的方式处理序列,即当前的隐藏状态是基于前一时间步的隐藏状态和当前的输入来计算。
循环神经网络 RNN
通过将隐藏状态从一个时间步传递到下一个时间步,以此捕获序列中的信息
长短期记忆 LSTM
引入了一种叫做“门”的机制来控制信息的流动,这使得LSTM解决RNN的梯度消失问题,能够捕获更长距离依赖。
Transformer
Self-Attention Mechanism
为每个元素分配一个权重,这个权重反映了其他元素对当前元素的重要性。
- 使用权重矩阵对每个元素生成query和key
- 对单个元素,算出该元素的query和其他元素的key的点积,运用softmax函数算出注意力分数
- 对注意力分数进行加权求和
Multi-Head Self-Attention
通过多个“头”进行处理,每个“头”都有自己的权重矩阵。然后,将所有头的输出拼接,通过线性变换产生最终的输出。
- 对于每个头,使用不同的权重矩阵对每个元素生成query和key
- 对单个元素,在每个头下,算出该元素的query和其他元素的key的点积,运用softmax函数算出注意力分数
- 将所有头的输出拼接在一起,对拼接的输出进行线性变换,得到最终的输出。
在自然语言处理任务中,一个头可能专注于捕捉句法依赖,另一个头可能专注于捕捉语义依赖。这种机制使模型能够更好地理解和生成复杂的文本。
Encoder
Encoder将输入转换为“上下文向量”
- Encoder由六层identical layers组成,每一层都由多头自注意力机制和前馈神经网络组成。
Decoder
Decoder接收编码器产生的上下文向量,将其转换为目标输出
- Decoder同样由六层identical layers组成,但每一层都在encoder的layer中针对encoder的输出添加了一个注意力机制。
- 这个额外的注意力机制使得decoder在生成每个输出词的时候,能够关注到输入的所有部分
Why Self-Attention
计算效率
RNN和LSTM的计算无法并行化。相比之下,Transformer的自注意力机制可以同时处理所有时间步,因此其计算可以高度并行化,提高计算效率。
捕捉长距离依赖
Transformer通过自注意力机制可以直接捕获序列中任何两个位置之间的依赖关系,无论距离多远。
全局上下文理解
Transformer中的每个元素的表示都由整个序列中的所有元素共同决定,这使得Transformer能更好地理解全局上下文。
更易于优化
由于RNN和LSTM的递归性质,它们在优化上可能面临梯度消失和梯度爆炸等问题。
同时RNN和LSTM需要一个一个处理时间步,而Transformer可以并行处理所有时间步,这使得Transformer的计算更小,可以使用标准的反向传播算法进行优化。
GPT发展史
GPT结构
参考Improving Language Understanding by Generative Pre-Training
GPT发展
| 模型名称 | 训练方法 | 特点 | 论文 |
|---|---|---|---|
| GPT-1 | 语言建模(预训练+微调) | 建立了GPT系列的核心架构;确定了使用上文预测下一单词的基本原则 | Improving Language Understanding Generative Pre-Training |
| GPT-2 | 语言建模,扩大模型参数到1.5B | 多任务语言模型 | Language Models are Unsupervised Multitask Learners |
| GPT-3 | 语言建模,扩大模型参数到175B | 提示补全,上下文学习,Few-shot Learning | Language Models are Few-Shot Learners |
| Instruct-GPT | 有监督微调,RLHF | 指令回答,Zero-shot Learning | Training language models to follow instructions with human feedback |
| Codex | 使用代码+文本训练 | 代码生成、chain-of-thought (CoT) | Evaluating Large Language Models Trained on Code |
| ChatGPT | 使用对话数据进行强化学习指令微调 | 对话历史建模 | |
| GPT-4 | 使用多模态数据 | 更强的性能、接受图像输入 | GPT-4 Technical Report |
提示(prompt)补全:根据输入的提示词,补全提示词的句子。
上下文学习(in-context learning):在输入中包含目标任务的描述或示例和正常输入测试用例,即使训练中不包含该任务数据,模型仍然可以产生符合期待的输出。
reinforcement learning from human feedback(RLHF):使用人工反馈对模型进行微调,使用这种微调可以将模型分化到不同技能上,如Chatgpt更擅长对话。这种微调并不会为模型注入新能力,而是解锁或引出原本存在在模型中的能力(在预训练中获得)。同时,人类微调实际上会导致模型在benchmark上的性能下降,但能够使模型向人类对齐,生成更符合人类需求的输出(零样本问答、道德约束、知识边界认知)。
指令回答(Responding):在经过RLHF之前,模型输出大部分是训练集中常见的提示补全模式。现在模型能够输出对prompt的合理回答,而不是相关却无用的句子。
chain-of-thought (CoT):常规的prompt策略基于上下文学习能力,在提问前为模型提供(问题-答案)文本对的样本。CoT在常规prompt的基础上,增加了从问题到答案的自然语言推导过程,从而提高模型的逐步推导能力。这种能力很可能使代码训练的副产物。目前只能从实验的角度证明相关性:GPT-3不能进行思维链推理,经过RLHF的GPT-3版本思维链推理同样很弱,而针对代码训练的模型具有很强的语言推理能力。
对话历史建模:ChatGPT使用对话数据集进行微调和RLHF,使得GPT具备了记忆过往对话的能力。
多模态模型:能够接受图像输出,理解图像内容。
GPT-2
- 参数数量提高到15亿
- 单向语言模型,采用了多任务方式,进一步提升模型的泛化能力
GPT-3
- 参数数量提高到1750 亿
- 强大的零样本和少样本学习能力
- 生成的文本质量非常高,实验表明人们很难区分其生成的文本是否由人类编写
GPT-4
Scaling Law
- KM scaling law. (2020)
- Chinchilla scaling law. (2022)
LLM优越性
为什么GPT-3没有引起人们普遍的关注?
GPT-3在2020年出现,但直到2022年LLM才进入大众视野。从实际性能上看,最初版本的GPT-3哪怕是其中最大的175B模型,其表现也未能超越经过微调的预训练语言模型(PLM)。而实验观测得到的比例定律让模型性能与规模挂钩,这意味着即使更改模型架构,也无法突破参数规模的限制,令模型难以取得重大的性能突破。
然而在2022年,Chain of Thought(CoT)和instruction tuning的出现打破了比例定律,使得LLM在规模有限的情况下出现了性能上的飞跃。
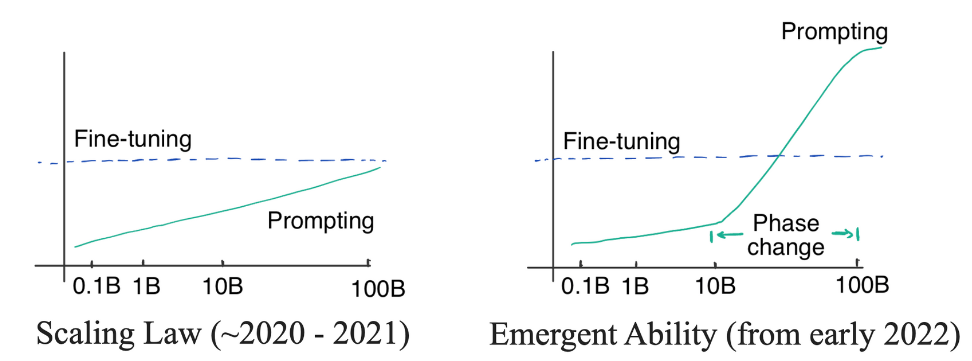
instruction tuning:使用指令数据集(包含指令形式的任务描述、输入输出对、几组示例)对模型进行fine-tune。而RLHF对应的微调被称为alignment tuning
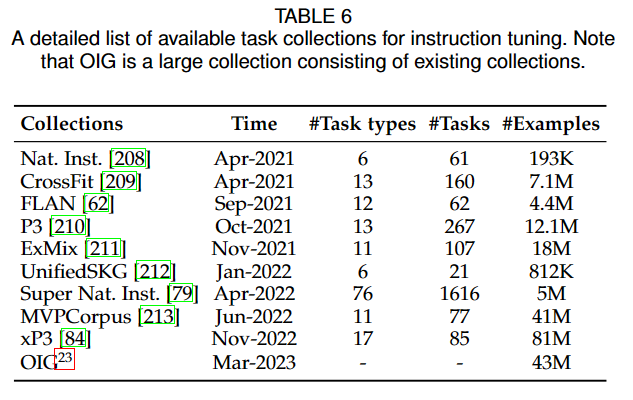
Emergent Ability
凝聚态物理里面常用涌现一词(英文emergent)来描述随着粒子数目增多突然出现的奇异现象。
涌现能力定义:小模型没有,只有大模型才有的能力。
涌现能力体现之处很多,我们重点关注的是那些(1)NLP领域长期努力但未能实现的;(2)其他NLP模型难以解决的;(3)关系到自然语言本质的;
(不同的综述对重要的涌现能力的定义存在微妙差异,但总体方向相似)
In-context learning (ICL)
上下文学习能力最早在GPT-3中引入。假设现在有一个新的任务,只需要给语言模型提供任务描述或几个示例,它可以产生预期的输出,而不需要额外的训练和梯度更新。
Instruction following
模型经过指令微调后,可以只根据指令形式的任务描述执行新任务,而不需要给出具体示例。最新研究中,想要实现指令服从,至少需要62B的模型。
不过对较小的模型,指令微调仍然可以能提高模型的性能。
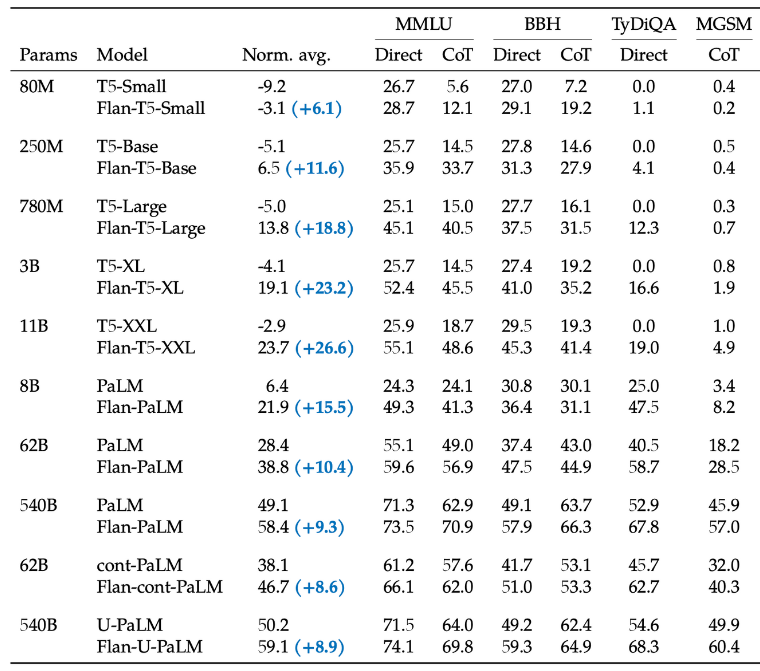
同时,指令微调可以显著改善模型的使用体验。
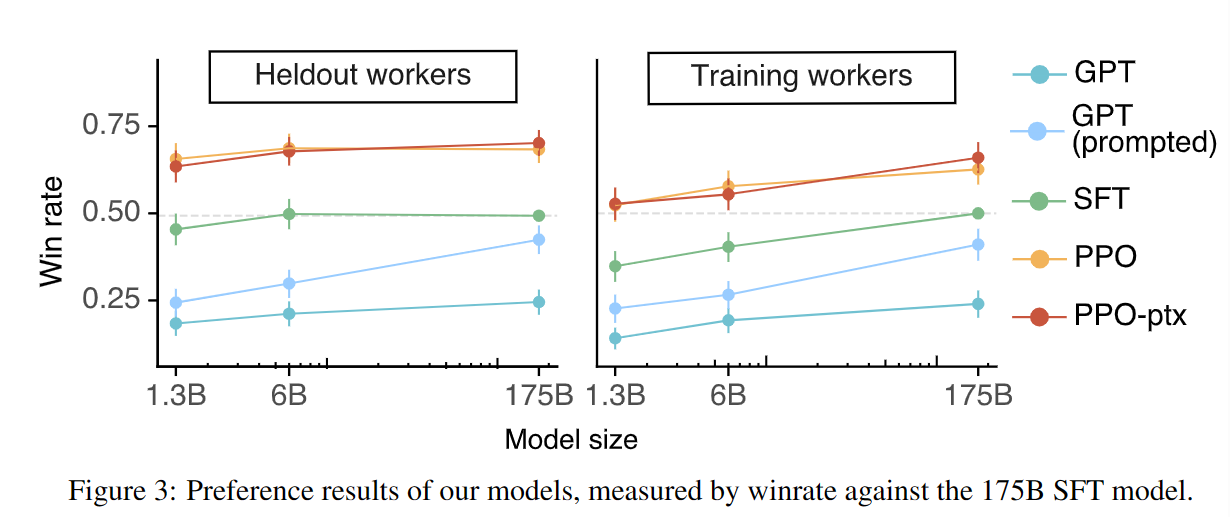
根据测试人员对模型在真实问题(从LLM API中收集)下回答的评价,强化学习(PPO)和监督微调(SFT)后的模型回答质量显著高于微调前。
Step-by-step reasoning
小型的语言模型通常很难解决需要多个推理步骤的复杂任务,如数学类相关的问题。通过使用chain-of-thought (CoT)策略,把带有中间步骤的样例加入到prompt中,LLM能够学习逐步推理直到产生最终答案的能力。
人工CoT:
- 输入
问题:小明有5个乒乓球,又买了2罐子乒乓球,每个罐子有3个乒乓球。请问小明现在有多少个乒乓球?
回答:小明从5个乒乓球开始,2个罐子,每罐3个,总共6个乒乓球。5+6=11。答案是11。
问题:锯一根10米长的木棒,每锯一段要2分钟。如果把这根木棒锯成相等的5段,请问需要多长时间?
回答:
- 输出
把木棒锯成5段,需要4次。锯一次2分钟,4次需要4*2=8 分钟。答案是8分钟。
Zero-shot CoT:
- 输入
问题:小明有5个乒乓球,又买了2罐子乒乓球,每个罐子有3个乒乓球。请问小明现在有多少个乒乓球?
回答:Let’s think step by step.
- 输出
Let’s think step by step. 把木棒锯成5段,需要4次。锯一次2分钟,4次需要4*2=8 分钟。答案是8分钟。
Auto-CoT

- 聚类选取有代表性的问题
- 对于每一个采样的问题拼接上“Let’s think step by step”(类似于 Zero-Shot-CoT )输入到语言模型,让语言模型生成中间推理步骤和答案,然后把这些所有采样的问题以及语言模型生成的中间推理步骤和答案全部拼接在一起,构成少样本学习的样例,最后再拼接上需要求解的问题一起输入到语言模型
这种方法显著提高了LLM解决问题的能力。根据实验分析,当模型规模大于62B时,CoT才比直接回答问题存在优势。如果模型规模较小,CoT反而会导致性能降低。(根据模型和任务的不同,这个临界值有差异)
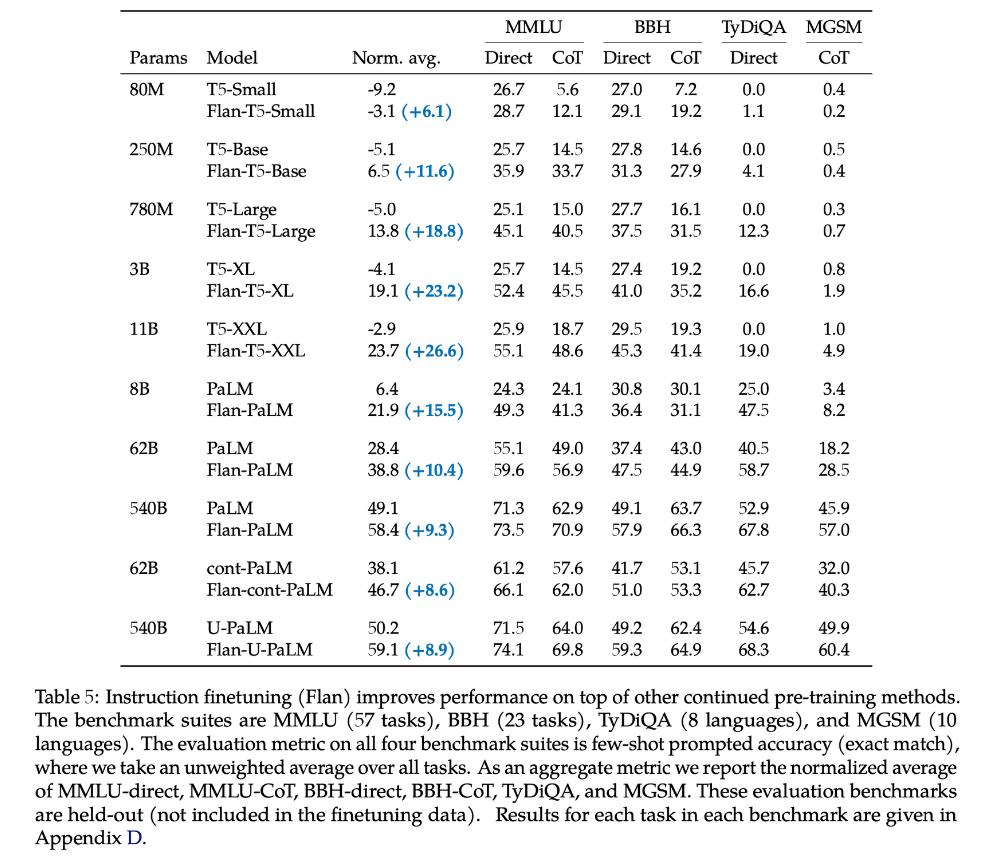
CoT能力来源分析
CoT出现的必要条件是模型达到一定规模,但规模并不是CoT的充分条件。
- 在175B的初始GPT-3、OPT、BLOOM等模型中都没有表现出CoT能力。(表现出CoT指采用CoT prompting后,模型性能比普通prompting和微调T5-11B更高)
CoT与训练集中的代码数据相关。
- 使用代码数据作为训练集,大小为GPT-3数据集28%的CodeX,展现了较强的链式推理能力。
CoT与指令微调相关
- GPT-3版本text-davinci-001链式推理能力差,而经过强化学习指令微调后的版本text-davinci-002,模型链式推理能力显著增强。
其他涌现能力(2022/8)
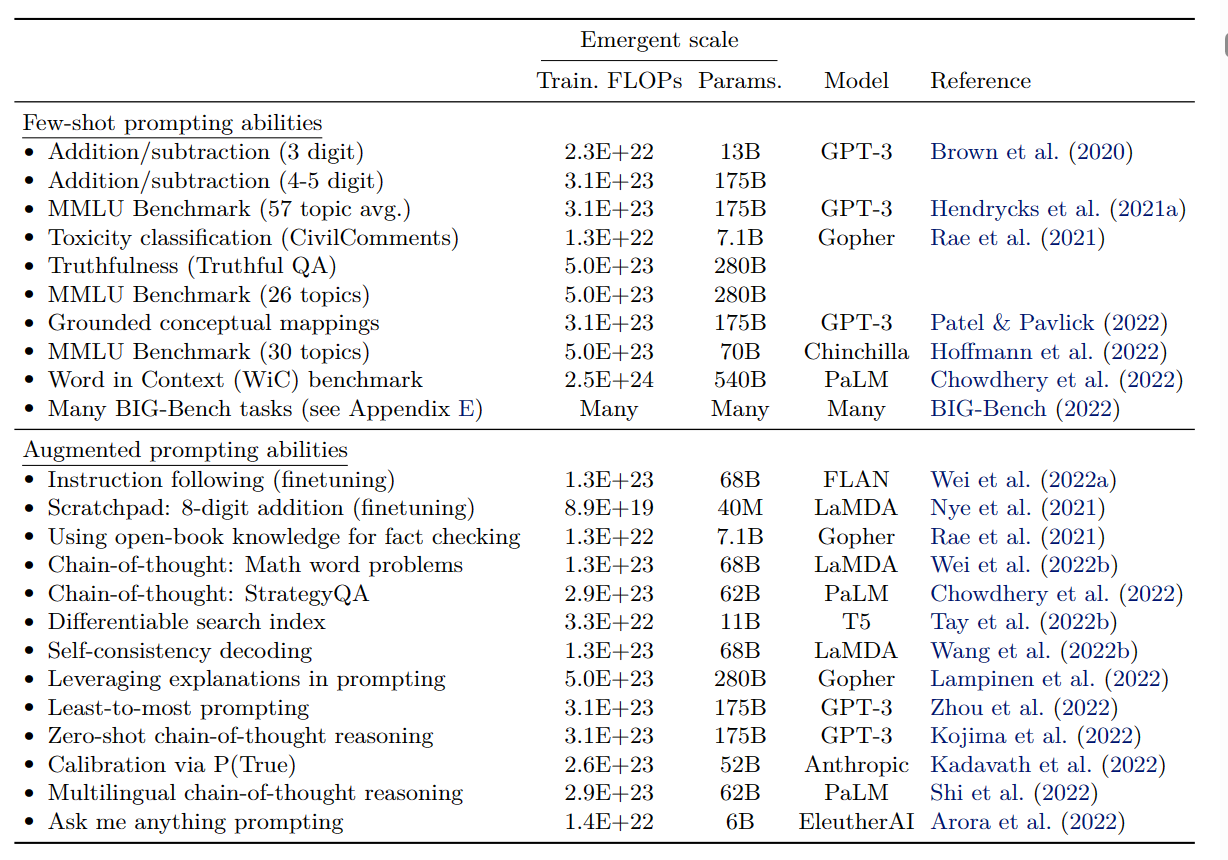
- Few-Shot Prompted Tasks. 在模型达到一定规模后,能通过few-shot prompting策略在benchmark上取得突破性的准确率增长
- Augmented Prompting Strategies. 能够增强LLM的prompting技巧。如果某些技巧在模型达到一定程度才能起作用,在此之前都没有效果甚至有害,那也称其为涌现能力
注意,一个LLM并不一定包含所有涌现能力,包含涌现能力也不说明LLM一定优于PLM。
Prompt Engineering
system prompt
引导模型生成与任务相关的响应
user prompt
为模型提供了具体的问题或要求
通过不断优化提示来提高模型的性能。
这种技术的优点是可以简单的对模型进行微调和定制,而无需重新训练整个模型。
【总结】LLM论文阅读(入门篇)-第一周
https://llm-frame-group.github.io/2023/06/07/【总结】LLM论文阅读(入门篇)-第一周/